The recent heatwave here in the UK brought huge growth to TidesX, my tide times app which serves over 150,000 tidal predictions each year to thousands of people. While the current backend scaled perfectly, the app had grown too popular for AWS’ free tier, and since I’ve been wanting to try out Cloudflare Workers for a while now, I decided that now was the perfect time to do it.
In this post, I’ll be briefly explaining how TidesX works, before discussing my experience migrating to the Cloudflare Workers platform (spoiler: it was great!).
The TidesX Backend
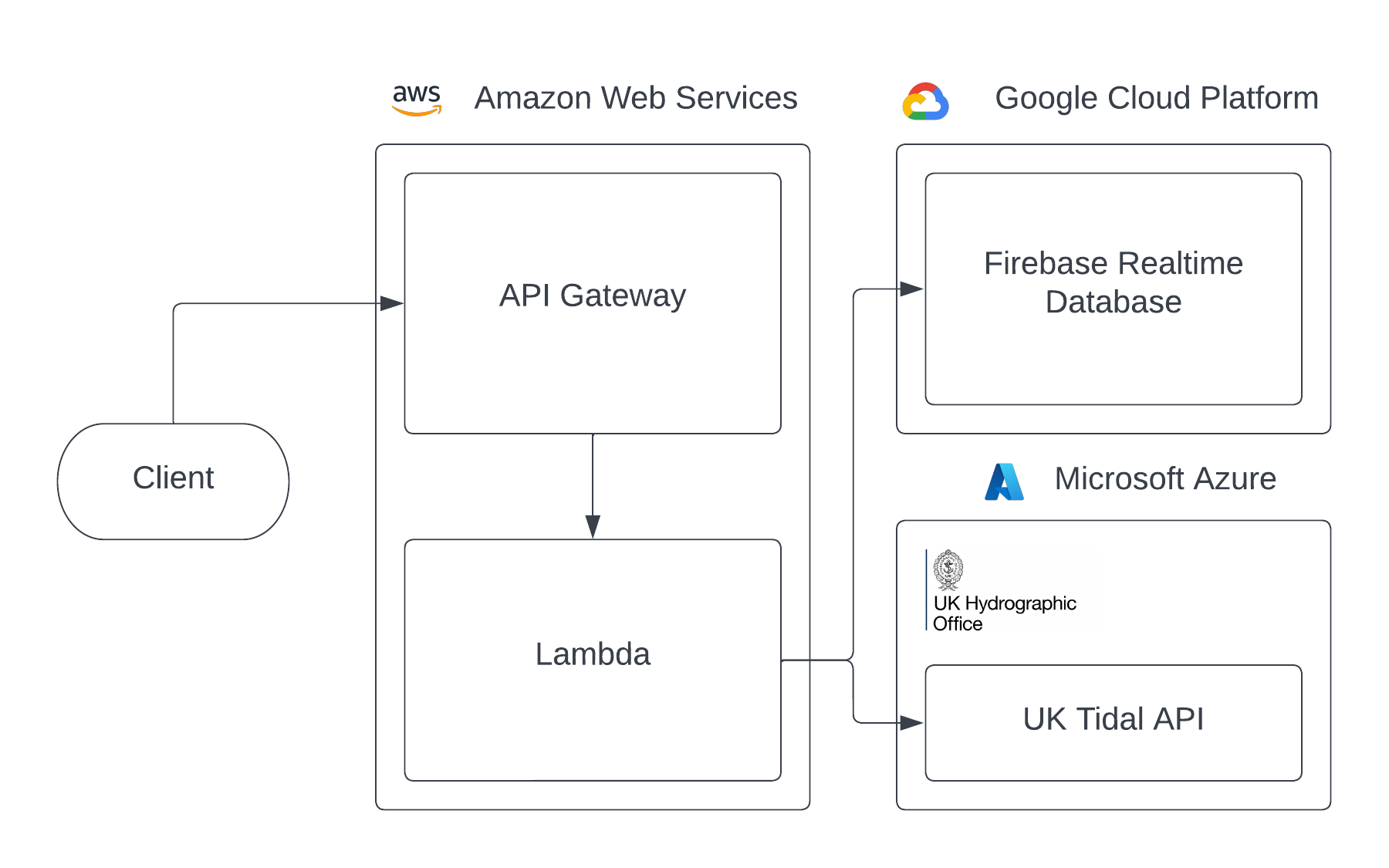
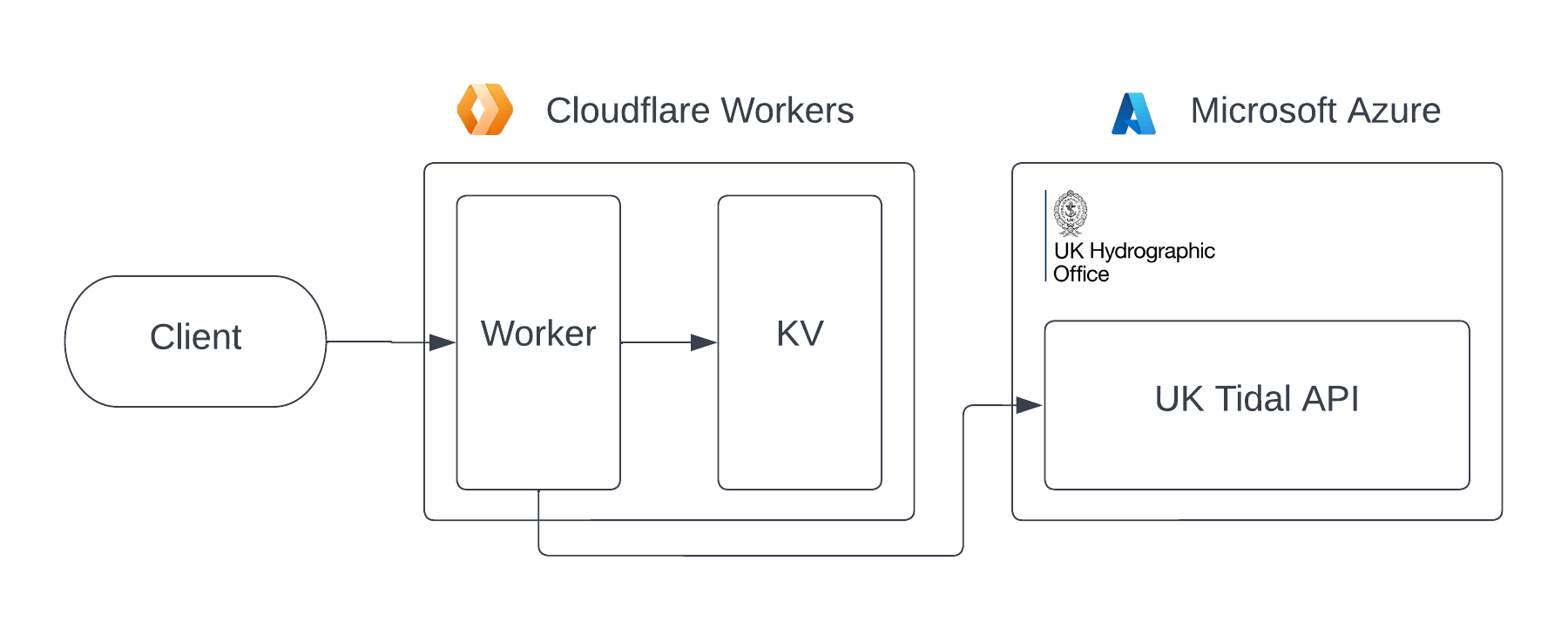
TidesX relies on the UK Hydrographic Office (UKHO) to provide its data. The UKHO provides an API, hosted on Azure, which allows us to access the tidal predictions for around 600 locations across the UK. However, the pricing is quite steep: after just 10,000 requests per month, you have to subscribe annually for either £120 for 20,000 requests per month or £300 for 100,000. TidesX’s entire selling point is that it is completely free and open-source, as well as having no ads, so we’re clearly limited to 10,000 requests per month if we don’t want to lose money!
Originally, the entire backend was a Python script on AWS Lambda, simply calling the API and returning the results. However, once traffic began to ramp up, it became apparent that we were going to quickly reach the 10,000 requests per month limit of the UKHO API.
There are only 600 locations that the API can give data for, so by dividing the 10,000 monthly requests evenly across them, I calculated that in the worst case (that is, if we had users from every location), we would be only be able to retrieve the tidal predictions for any given location once every 48 hours. As the tidal predictions only change every 24 hours, this would mean that, at worst, users would see one day less of predictions (6 days instead of 7). This seemed like a good tradeoff, so I set about implementing a caching mechanism.
As the cache would need to be very quick, serve many reads but very few writes, and most importantly, be free, I chose to use Google Firebase Realtime Database, which offers 10GB of data transfer per month. Each location only has around 5KB of data (the tidal predictions for one week), so the database can serve 2,000,000 requests per month, which is more than enough. After hooking this up with AWS Lambda, the backend successfully scaled and worked perfectly at no cost for about a year.
At this point, the backend architecture looked like this:
The Problem
After 12 months I noticed that I was being charged a little bit each month by AWS. While AWS offers 1,000,000 free requests to Lambda functions per month as part of their “Always Free” offering, it was not clear at all that after 12 months, they start charging for use of their API Gateway service - as far as I could tell, the only way to actually call Lambda functions from the outside!
Feeling a bit annoyed at this unwelcome surprise, I decided to migrate the backend to Cloudflare Workers.
Setting Up Cloudflare Workers
My original plan was to simply swap out AWS Lambda with Cloudflare Workers, and keep Firebase Realtime Database as the cache. However, as I was reading about Cloudflare Workers, I discovered KV, their low-latency key-value data store, which offers 1,000 writes and 100,000 reads per day. Keeping everything in one place makes it a lot easier to manage, so I decided to also abandon Firebase Realtime Database in favour of KV.
The new architecture looks like this:
Cloudflare Workers allows you to write code in a vast number of languages, including JavaScript, TypeScript, Rust, Python, C and more. However, the platform only natively supports JavaScript and WASM, so any other languages must be compiled to one of the two. While I do absolutely love Rust, I decided to write the new backend in TypeScript as it’s a lot easier to work with, especially when dealing with complex JSON data.
Setting up the project was as simple as installing Wrangler, the Cloudflare Workers CLI, logging in, and running the following commands:
$ wrangler init tidesx-api # initialise the project
$ wrangler kv:namespace create tidesx # create the KV namespace
In order to access the KV namespace from the Worker, it needed to be bound to the project in the wrangler.toml file. This was done by adding the following line.
kv_namespaces = [
{ binding = "TIDESX", id = "<namespace ID goes here>" }
]
All in all, the setup was very simple, and the documentation was very clear and helpful along the way.
Writing the Worker
Since the old Lambda function was written in Python, and I was writing the new Worker in TypeScript, I couldn’t just copy and paste the code. Furthermore, since I was migrating to KV from Firebase Realtime Database too, I needed to use the KV API as well. Fortunately, this was extremely well documented, and I had no trouble using it.
The Worker needs to respond to HTTP requests, so I needed to implement the fetch handler function. This takes a Request object, as well as an Env object which contains the KV namespace, and returns a promise resolving to a Response object.
export interface Env {
TIDESX: KVNamespace;
}
export default {
async fetch(request: Request, env: Env): Promise<Response> {
// TODO
},
};
The fetch function needs to do three things.
- Parse the query string to get the location ID.
- Retrieve the tidal predictions for the location from KV. If they don’t exist, or have expired, call the UKHO API to get them, then cache them.
- Return the tidal predictions as a JSON response.
The first of these was very simple using JavaScript’s built-in URL parsing.
const { searchParams } = new URL(request.url);
const id = searchParams.get("id");
if (!id) {
console.log(`Invalid ID: ${id}`);
return new Response("Missing ID", { status: 400 });
}
Getting the cached tidal predictions from KV was also simple thanks to the intuitive API.
const cachedValue = await env.TIDESX.get(id);
Then, we need to verify if the cached value is fresh. If it is, we can simply return it.
const currentTime = new Date().getTime();
if (cachedValue) {
const cachedJson = JSON.parse(cachedValue);
if (cachedJson.timestamp + CACHE_DURATION > currentTime) {
const data = cachedJson.data;
console.log(`Cache hit for ${id}`);
return new Response(JSON.stringify(data), {
headers: { "Content-Type": "application/json" }
});
}
console.log(`Cache stale for ${id}, refreshing`);
}
At this point, the function will have returned if the cache successfully served the data, so if not, we need to call the UKHO API to refresh the cache.
const response = await fetch(API_URL.replace("{}", id), {
headers: { "Ocp-Apim-Subscription-Key": API_KEY }
});
// If the response from the API failed, return a 404
if (response.status !== 200) {
console.log(`API error for ${id}: ${await response.text()}`);
return new Response("Not found", { status: 404 });
}
Finally, we just need to cache the response and return it to the user.
const responseJson = await response.json();
const cacheValue = JSON.stringify({
timestamp: currentTime,
data: responseJson
});
await env.TIDESX.put(id, cacheValue);
console.log(`Cache updated for ${id}`);
return new Response(JSON.stringify(responseJson), {
headers: { "Content-Type": "application/json" }
});
Testing and Deploying the Worker
The Worker can be run locally using the wrangler dev command. After testing it and ensuring that it worked, I deployed it to Cloudflare’s network with the wrangler publish command.
$ wrangler publish --name tidesx-api
Finally, I updated the TidesX front-end to call the Worker instead of the Lambda function. I tested it on my personal phone, and it worked fine, so I cautiously deployed it to production and monitored it closely for 24 hours. After 24 hours, it had served around 500 requests for 100 different locations, all of which had worked perfectly.
I also noticed that the average request took just 3ms to complete, which is way faster than the Lambda function, which usually took around 100ms. This is probably because KV is part of the same network as the Worker, whereas the Lambda function had to get data from Google Cloud each time.
Conclusion
In conclusion, the migration to Cloudflare Workers was a good choice, both for performance and for cost. It was extremely easy to get going, and I ran into very few issues along the way. While KV’s 1,000 daily writes limit is a bit low for most applications, I was lucky in that it was the perfect amount for TidesX. If this post was helpful to you, please consider sharing it with others who may be interested!